
5 Coisas Que Você Não Sabia Que Pode Fazer Com Traceflow
Gerenciar uma rede moderna definida por software significa navegar por uma arquitetura em várias camadas. Quando o tráfego de rede desaparece entre overlays, firewalls distribuídos e entregas físicas (handoffs), muitos engenheiros ainda recorrem a métodos tradicionais de solução de problemas – acessando hosts ESXi e Edge Nodes via SSH, executando pktcap-uw ou analisando saídas de esxcli. Embora essas ferramentas sejam vitais, elas também consomem muito tempo. O NSX Traceflow tem sido um recurso nativo em sua pilha de rede virtual VCF há algum tempo, mas continua sendo uma ferramenta subutilizada no arsenal.
O Traceflow não é apenas um traceroute gráfico. Diferente de um traceroute tradicional que depende do sistema operacional guest para gerar um pacote e aguarda mensagens ICMP "Time Exceeded" de roteadores físicos, o Traceflow injeta um pacote sintético, especialmente marcado, diretamente no plano de dados do hypervisor e monitora os pontos de observação NSX relevantes no caminho de encaminhamento. Ele não depende de ICMP. Em vez disso, cada componente de rede virtual NSX que toca o pacote – do Distributed Firewall (DFW) às regras lógicas de NAT – lê a tag e reporta sua ação exata diretamente ao NSX Manager.
Aqui estão 5 maneiras de usar o NSX Traceflow:
1. Testar a Conectividade de Rede de Entrada (Ingresso Através do Roteador Tier-0)
Além do teste de tráfego East-West, o Traceflow pode ser usado para testar o tráfego de entrada North-South originado de fora da rede virtual.
O Caso de Uso: Você precisa verificar se o tráfego de um cliente externo na rede física pode alcançar um destino virtual interno específico, como um servidor web recém-implantado.
Como Funciona: O Traceflow permite injetar tráfego sintético diretamente nos uplinks do Tier-0 (T0) que se conectam à rede física. Você pode especificar um endereço IP externo como origem. O Traceflow empurrará o pacote através da porta de ingresso do T0 e rastreará sua jornada através do roteador Tier-1, quaisquer Edge Nodes e hosts ESX no caminho, o Distributed Firewall (DFW) e, finalmente, até a VM de destino. Se usuários externos estiverem relatando falhas de conectividade, esta é a maneira mais rápida de provar se a topologia de rede virtual e roteamento está aceitando e roteando o tráfego de entrada corretamente.
Exemplo e Saída de Traceflow de Entrada Vamos ver como configurar um trace de entrada direcionado a uma VM em um segmento de overlay. O objetivo é validar o caminho de roteamento e encaminhamento para o tráfego originado de fora das redes virtuais. Para configurar isso, defina a Origem do Traceflow para usar uma porta Uplink do Tier-0 Edge. Em seguida, sobrescreva manualmente o campo de endereço IP de origem para representar um cliente externo – por exemplo, 8.8.8.8. Você pode substituir isso por qualquer endereço IP público ou corporativo roteável que deseja simular.
Figura 1 – Traceflow testando o tráfego de ingresso através do T0
Para que esta injeção sintética funcione, há dois requisitos de roteamento rigorosos que você deve atender:
- Roteamento para o Destino: Certifique-se de selecionar uma porta uplink no gateway Tier-0 correto que tenha uma rota para a sub-rede onde a VM de destino reside.
- Verificações de Reverse Path Forwarding (RPF): O gateway Tier-0 deve ter uma rota para o IP de origem (ou seja, o tráfego que sai do ambiente deve saber como alcançar 8.8.8.8), caso contrário, o pacote será descartado pela verificação de Reverse Path Forwarding (RPF) do Tier-0, e sua tabela de observação mostrará um erro "Dropped by IP". Se você estiver apenas executando um teste isolado e o ambiente não tiver uma rota para o IP de origem ou uma rota padrão, você pode temporariamente contornar isso desabilitando a verificação de RPF na interface do Tier-0.
A saída resultante do Traceflow abaixo fornece uma visão interessante dos detalhes internos da pilha de rede virtual. Você obtém uma visualização hop-by-hop à medida que o pacote entra no Tier-0, atravessa o roteador Tier-1, sai do Edge Node e cruza o overlay para o host ESXi de destino. Finalmente, você o vê explicitamente permitido pelo DFW e entregue com sucesso à vNIC da VM. A melhor parte? Você coleta todos esses dados definitivos de roteamento e encaminhamento sem exigir nenhuma captura de pacote, tempo de inatividade ou coordenação do proprietário da VM.
Figura 2 – Observações de Traceflow de Entrada
2. Identificar a Regra de Firewall que Descartou Pacotes
Caçar pacotes descartados em um ambiente micro-segmentado pode ser tedioso. A solução de problemas tradicional envolve acessar o host, monitorar os dfwpktlogs e procurar (grepping) por endereços IP ou ações de descarte.
O Caso de Uso: Um proprietário de aplicativo alega que o firewall virtual está bloqueando seu tráfego, mas você tem centenas de regras em sua tabela de políticas e precisa verificar rapidamente se uma regra de FW está causando o problema.
Como Funciona: Quando o Traceflow injeta um pacote, ele avalia esse pacote em relação ao estado real do plano de dados. Se o tráfego atingir uma regra de "Drop" ou "Reject" no Distributed Firewall (DFW) ou uma política de Gateway Firewall, o caminho gráfico no mapa de topologia do Traceflow terminará no componente exato onde o bloqueio ocorreu. Mais importante, na tabela de observação abaixo do mapa, o Traceflow registra a ação como "Dropped" e exibe o ID exato da Regra que causou o descarte. Você não precisa fazer engenharia reversa manual para descobrir a quais Security Groups ou IP Sets uma VM pertence apenas para encontrar a política correspondente; você pode pegar esse ID de Regra exato, encontrá-lo na UI e corrigir a regra imediatamente.
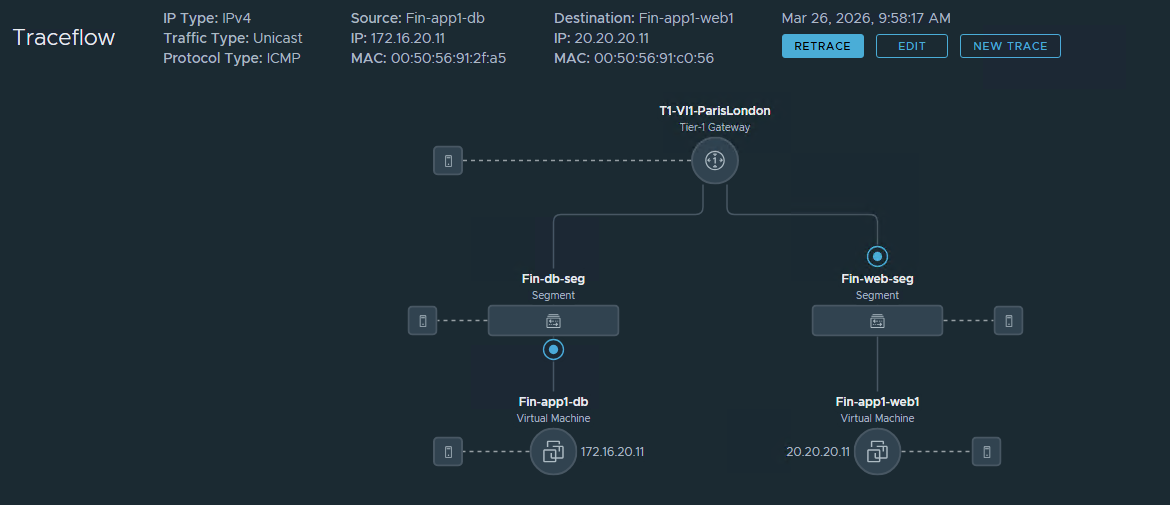
Exemplo e Saída de Identificação de Regra de FW Vamos ver um exemplo prático. Suponha que uma regra de Gateway Firewall esteja configurada em um roteador Tier-1 para descartar qualquer tráfego de saída originado do endereço IP 10.9.9.11. Ao executar um Traceflow que corresponda a esse IP de origem, a ferramenta sinaliza imediatamente o descarte.
Figura 3 – Configuração da regra de descarte do Gateway Firewall
Figura 4 – Observações do Traceflow mostrando descarte por regra de Firewall
Conforme mostrado na tabela de observação, o Traceflow aponta onde o pacote foi parado (no roteador Tier-1) e fornece o ID de Regra específico que impôs o descarte. Isso elimina as suposições na solução de problemas de política.
3. Isolar o Domínio de Falha (Localizar o Ponto de Saída Físico)
Ao solucionar problemas de conectividade North-South relacionados a aplicativos em execução na infraestrutura virtual, determinar se a perda de pacotes está ocorrendo dentro do overlay virtual ou do underlay físico é uma parte padrão do processo. Isolar rapidamente o domínio de falha para a rede virtual ou física é fundamental para uma resolução eficiente.
O Caso de Uso: Você precisa de dados acionáveis para determinar se a infraestrutura virtual está roteando com sucesso este tráfego North-South para fora do ambiente e entregando-o à malha física.
Como Funciona: O Traceflow faz a ponte entre os limites lógicos e físicos, rastreando um pacote sintético até o endpoint do túnel do host (TEP) ou o TEP do Edge node. Na tabela de observação, ele exibe a travessia do pacote pela rede virtual, identifica o uplink usado para sair do ambiente e registra explicitamente quando o pacote é "Delivered" (entregue) em direção à rede física. Se o Traceflow indicar uma entrega bem-sucedida ao cabo físico, ele valida o caminho do tráfego virtual. Embora esta seja apenas uma peça do quebra-cabeça maior da solução de problemas, ela fornece um ponto de dados altamente valioso para ajudar na colaboração com a equipe de rede física.
Exemplo e Saída de Traceflow de Saída No exemplo a seguir, iniciamos um Traceflow da mesma VM usada no cenário anterior do firewall, direcionando um endereço IP externo (192.19.189.10) na rede física. Os resultados mostram o pacote saindo do roteador Tier-0 (T0) via uplink do Edge, resultando em um status de observação "Delivered". Este status significa que o Traceflow observou o pacote sintético saindo da pilha de rede virtual do Edge node. Embora não garanta que o pacote atingiu seu destino final na rede física, ele confirma que a infraestrutura virtual completou suas funções de roteamento e encaminhamento para o IP de origem e destino. Em última análise, isso fornece um ponto de dados sólido sugerindo que o foco da solução de problemas deve mudar para a rede física.
É importante entender por que essa visibilidade termina no limite físico. O Traceflow depende de componentes ao longo do caminho de dados para observar o pacote sintético e reportar ao plano de gerenciamento. Como os dispositivos de rede física externos atualmente não processam ou reportam esses pacotes específicos do Traceflow, nenhuma telemetria hop-by-hop adicional está disponível uma vez que o tráfego sai da infraestrutura virtual.
4. Encontrar a Tradução NAT Exata no Caminho
A Network Address Translation (NAT) pode ser difícil de solucionar porque os endereços IP de origem ou destino mudam no meio do caminho. O Traceflow é uma ferramenta inestimável para rastrear a tradução NAT para um fluxo à medida que ele passa por roteadores lógicos Tier-0 ou Tier-1, especificamente quando serviços como Load Balancer Virtual IPs (VIPs) ou Egress SNATs estão modificando ativamente os cabeçalhos dos pacotes.
O Caso de Uso: O tráfego está caindo no meio de uma conexão que entra ou sai do seu ambiente, e você não percebeu que um SNAT sobreposto ou uma regra DNAT mal configurada está traduzindo o pacote para um endereço IP inesperado.
Como Funciona: Na solução de problemas de rede tradicional, a verificação de regras NAT frequentemente exige a execução de capturas de pacotes simultâneas em várias interfaces e a correlação manual dos endereços IP antes e depois. O Traceflow elimina essa correlação manual visualizando todo o ciclo de vida virtual do pacote em uma única exibição. À medida que o pacote sintético atravessa os roteadores lógicos, a tabela de observação sinaliza o hop exato onde ocorre um Source NAT (SNAT) ou Destination NAT (DNAT):
- Tráfego de Entrada (DNAT): Se o tráfego externo estiver atingindo um VIP de Load Balancer NSX voltado para o público, o Traceflow mostrará exatamente para qual IP de backend interno o VIP foi traduzido, confirmando se a lógica de roteamento de entrada está correta.
- Tráfego de Saída (SNAT): Se as cargas de trabalho internas estiverem acessando redes externas, o Traceflow revela o IP de origem traduzido exato aplicado no gateway. Isso é fundamental para provar às equipes de firewall externas qual endereço IP elas precisam permitir (allowlist).
O Traceflow destaca explicitamente os pontos de observação onde o NAT ocorre, fornecendo informações detalhadas sobre a regra NAT aplicada e o endereço IP traduzido resultante. Isso o torna um método simples, mas valioso, para validar proativamente a lógica de encaminhamento de rede antes mesmo de um aplicativo ser implantado.
Exemplo e Saída de Caso de Uso NAT No exemplo a seguir, uma regra SNAT é configurada para fluxos de tráfego com um IP de origem de 10.9.9.11 e um destino de 8.8.8.8 na porta 80. Quando um Traceflow é executado correspondendo a esse padrão de tráfego exato, os resultados mostram a operação SNAT ocorrendo no roteador Tier-1, juntamente com o novo endereço IP traduzido e o ID da regra específica que foi aplicada.
Figura 6 – Exemplo de configuração NAT no roteador Tier-1
Figura 7 – Resultados do Traceflow para fluxo de tráfego NATeado
5. Automatizar a Solução de Problemas (Integrando o Traceflow via API)
Embora o Traceflow seja altamente visível e fácil de usar na UI do NSX Manager, ele não se restringe a operações manuais de apontar e clicar. Todo o motor do Traceflow é exposto via NSX REST API, o que abre poderosas possibilidades para solução de problemas programática em escala.
O Caso de Uso: Um proprietário de aplicativo relata uma queda de conectividade. Em vez de um engenheiro de rede Nível 3 fazer login manualmente no NSX Manager para investigar cada alerta, você deseja automatizar o processo de triagem inicial e capacitar o suporte Nível 1.
Como Funciona: Ao integrar a API do Traceflow com uma plataforma de IT Service Management (ITSM) (como ServiceNow) ou um bot ChatOps personalizado (via Slack ou Microsoft Teams), você pode automatizar a fase de coleta de dados da solução de problemas. Quando um usuário envia um ticket informando que "Web-VM-01 não consegue alcançar DB-VM-01", o sistema de tickets pode acionar automaticamente um script (usando Python, Postman ou PowerCLI) para executar uma chamada de API do Traceflow entre essas máquinas virtuais específicas. O NSX injeta o pacote sintético, rastreia o caminho e retorna a saída JSON. O script analisa essa saída e anexa automaticamente os resultados diretamente ao ticket – destacando instantaneamente se o pacote foi entregue com sucesso, descartado por uma regra específica do Distributed Firewall (DFW) ou perdido em um hop específico.
Isso oferece vários benefícios importantes:
- Tempo Médio de Resolução (MTTR) Mais Rápido: A equipe de rede tem o ponto de descarte exato e o ID da regra esperando por eles ao abrir o ticket.
- Triagem de Autoatendimento: Utilizando contas de serviço, permite que proprietários de aplicativos ou equipes de suporte Nível 1 validem com segurança os caminhos de rede sem exigir acesso administrativo à UI do NSX.
- Validação em Massa: Após uma migração de data center em larga escala ou uma alteração complexa de regras DFW, scripts podem executar programaticamente centenas de Traceflows entre camadas de aplicativos para verificar rapidamente se a nova topologia está roteando corretamente.
Para endpoints exatos, payloads JSON e requisitos de parâmetros para construir esses fluxos de trabalho automatizados, consulte o Guia Oficial da REST API do NSX-T Data Center no Broadcom Developer Portal.
Considerações Finais
O Traceflow é muito mais do que um teste de ping básico – ele fornece visibilidade crítica e pontos de dados acionáveis para entender sua rede virtual. Seja validando regras NAT complexas, preenchendo a lacuna com equipes de rede física ou automatizando a triagem do helpdesk via REST API, ele reduz significativamente o ruído da solução de problemas de rede.
Quando o próximo ticket de conectividade chegar, considere começar com o Traceflow antes de implantar capturas de pacotes simultâneas. Ao visualizar todo o ciclo de vida virtual de um pacote em uma única exibição, o Traceflow elimina a necessidade de correlação manual, tornando-o um primeiro passo altamente eficaz para isolar rapidamente o domínio de falha e reduzir seu Tempo Médio de Resolução (MTTR). Se sua solução de problemas exigir a análise de padrões de tráfego históricos e fluxos IPFIX ativos – o recurso Path Topology no VCF Operations for Networks também pode servir como uma poderosa ferramenta complementar para visibilidade profunda de ponta a ponta.
Equipar sua equipe com essas ferramentas integradas transforma a solução de problemas de rede de um jogo de adivinhação frustrante em um processo otimizado e baseado em dados.
Descubra mais no Blog do VMware Cloud Foundation (VCF). Assine para receber as últimas postagens por e-mail.
Digite seu e-mail… Assinar
Precisa de ajuda com suas soluções de TI?
A VirtuAllIT Solutions oferece consultoria especializada em virtualização, cloud computing e infraestrutura tecnológica.