
O Novo Paradigma: MLPerf 5.1 Confirma que VCF é o Futuro do Desempenho de IA/ML
Desempenho de IA/ML em VMware Cloud Foundation (VCF) 9.0: Resultados do MLPerf Inference 5.1
A Broadcom colaborou com a Dell, Intel, NVIDIA e SuperMicro para destacar as vantagens da virtualização, entregando resultados notáveis no MLPerf Inference v5.1. O VMware Cloud Foundation (VCF) 9.0 alcançou desempenho comparável a ambientes bare metal nos principais benchmarks de IA — incluindo Speech-to-Text (Whisper), Text-to-Video (Stable Diffusion XL), LLMs (Llama 3.1-405B e Llama 2-70B), Graph Neural Networks (R-GAT) e Computer Vision (RetinaNet).
Esses resultados foram obtidos em soluções de GPU e CPU com 8x H200 GPUs virtualizadas da NVIDIA, 8x B200 GPUs em passthrough/DirectPath I/O, e processadores Xeon 6787P de dual-socket virtualizados da Intel. Para a comparação bruta das métricas relevantes, consulte os resultados oficiais do MLCommons Inference 5.1.
Com esses resultados, a Broadcom demonstra mais uma vez que os ambientes virtualizados do VCF apresentam desempenho equivalente ao bare metal, permitindo que os clientes se beneficiem da maior Agilidade, Disponibilidade e Flexibilidade que o VCF oferece, ao mesmo tempo que aproveitam um excelente desempenho.
VMware Private AI e Democratização da Inovação
O VMware Private AI é uma abordagem arquitetônica que equilibra os ganhos de negócios da IA com as necessidades de privacidade e compliance da organização. Construída sobre a plataforma de private cloud líder do setor, o VMware Cloud Foundation (VCF), essa abordagem garante a privacidade e o controle dos dados, a escolha de soluções de IA open-source e comerciais, e um ótimo custo, desempenho e compliance.
A Broadcom visa democratizar a IA e impulsionar a inovação de negócios para todas as organizações. O VMware Private AI permite que as empresas usem uma variedade de soluções de IA para seus ambientes — NVIDIA, AMD, Intel, repositórios da comunidade open-source e fornecedores independentes de software. Com o VMware Private AI, as empresas podem implantar com confiança, sabendo que a Broadcom estabeleceu parcerias com os principais provedores de IA.
A Broadcom traz o poder de seus parceiros Dell, Intel, NVIDIA e SuperMicro para o VCF, simplificando o gerenciamento de data centers acelerados por IA e permitindo o desenvolvimento e a execução eficientes de aplicações para workloads exigentes de AI/ML.
Apresentamos três configurações no VCF: o SuperMicro GPU SuperServer AS-4126GS-NBR-LCC com 8xB200s interligadas por NVLink em DirectPath I/O, o Dell PowerEdge XE9680 com 8xH200s interligadas por NVLink no modo vGPU, e uma VM 1-node-2S-GNR_86C_ESXi_172VCPU com CPUs INTEL(R) XEON(R) 6787P de 86 cores.
Desempenho do MLPerf Inference 5.1 com VCF no Servidor SuperMicro com NVIDIA 8xB200
O VCF suporta tanto as tecnologias DirectPath I/O quanto NVIDIA Virtual GPU (vGPU) para habilitar GPUs para IA e outros workloads baseados em GPU. Para uma demonstração de desempenho de IA com NVIDIA B200 GPUs, escolhemos o DirectPath I/O para nosso benchmarking do MLPerf Inference.
Executamos workloads do MLPerf Inference em um SuperMicro SuperServer AS-4126GS-NBR-LCC com oito NVIDIA SXM B200 180GB HBM3e GPUs utilizando o VCF 9.0.0. A Tabela 1 mostra as configurações de hardware usadas para executar os workloads do MLPerf Inference 5.1 nos sistemas bare metal e virtualizados. Os benchmarks foram otimizados com o NVIDIA TensorRT-LLM.
O TensorRT-LLM consiste no compilador de deep learning TensorRT e inclui kernels otimizados, etapas de pré e pós-processamento, e primitivas de comunicação multi-GPU/multi-nó para um desempenho revolucionário em NVIDIA GPUs.
Tabela 1. Hardware e software para testes MLPerf bare metal e virtualizados
| Bare Metal | Virtual System | |
|---|---|---|
| SuperMicro GPU SuperServer | SYS-422GA-NBRT-LCC | AS-4126GS-NBR-LCC |
| Processors | 2x Intel Xeon 6960P 72 Core | 2x AMD EPYC 9965 192 Core |
| Logical processors | 144 | 192 de 384 (50%) alocados para a VM para inferência (com utilização de CPU abaixo de 10%). Portanto, 192 disponíveis para outras VMs/workloads com isolamento total devido à virtualização. |
| GPUs | 8x NVIDIA B200 180GB HBM3e | DirectPath I/O 8x NVIDIA B200 180GB HBM3e |
| Accelerator Interconnect | 18x NVIDIA 5th Gen NVLinks, 14.4 TB/s aggregated bandwidth | 18x NVIDIA 5th Gen NVLinks, 14.4 TB/s aggregated bandwidth |
| Memory | 2.3 TB Host Memory | 3 TB |
| Storage | 4x 15.36 TB NVMe SSD | 4x 13.97 TB NVMe SSD |
| OS | Ubuntu 24.04 | Ubuntu 24.04 VM on VCF/ESXi 9.0.0.0.24755229 |
| CUDA | 12.9 CUDA and Driver 575.57.08 | 12.8 CUDA and Driver 570.158.01 |
| TensorRT | TensorRT 10.1 | TensorRT 10.1 |
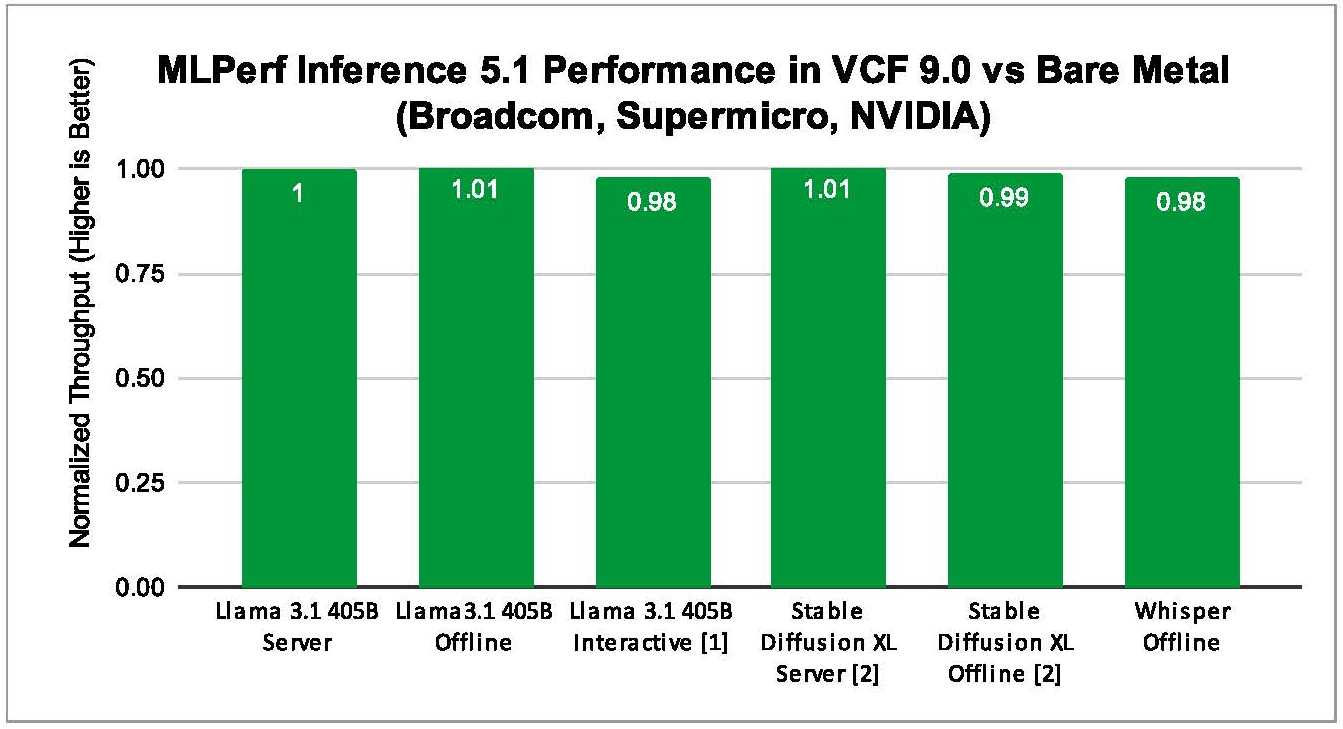
A Figura 1 demonstra que os workloads de Inferência AI/ML de diversos domínios, como LLM (Llama 3.1 com 405 bilhões de parâmetros, Speech2Text (Whisper da OpenAI), Text2Images (Stable Diffusion XL)), obtêm um desempenho em VCF comparável ao bare metal. Ao executar workloads de AI/ML no VCF, o cliente obtém os benefícios de gerenciamento de data center do VCF, aproveitando o desempenho equivalente ao bare metal.
Desempenho do MLPerf Inference 5.1 com VCF no Servidor Dell com NVIDIA 8xH200
A Broadcom oferece suporte a clientes empresariais que possuem infraestrutura de IA de diferentes fornecedores de hardware. Nesta rodada de submissão do MLPerf Inference 5.1, colaboramos com a NVIDIA e a Dell para demonstrar o VCF 9.0 como uma excelente plataforma para IA, especialmente para workloads de IA generativa.
Escolhemos o vGPU para nosso benchmarking para apresentar outra opção de implantação que os clientes podem escolher no VCF 9.0. O recurso vGPU integrado ao VCF oferece vários benefícios para a implantação e o gerenciamento da infraestrutura de IA.
Primeiro, o VCF cria grupos de dispositivos de 2-GPU, 4-GPU e 8-GPU usando NVLink e NVSwitch. Esses grupos de dispositivos podem ser alocados para diferentes VMs. Isso proporciona flexibilidade na alocação de recursos de GPU para a VM para melhor atender aos requisitos do workload e aumenta a utilização da GPU.
Segundo, o vGPU permite que múltiplas VMs compartilhem recursos de GPU no mesmo host. O vGPU aloca a cada VM uma porção da memória da GPU e/ou capacidade de computação da GPU especificada pelo perfil vGPU. Isso permite que múltiplos workloads menores compartilhem uma única GPU com base em seus requisitos de memória e computação. Isso ajuda a aumentar a consolidação do sistema, maximizar a utilização de recursos e economizar custos de implantação da infraestrutura de IA.
Terceiro, o vGPU oferece uma maneira flexível de gerenciar data centers com GPUs, suportando suspend/resume e VMware vMotion de VMs (nota: o vMotion é suportado apenas quando os workloads de IA não utilizam o recurso Unified Virtual Memory GPU).
Por último, mas não menos importante, o vGPU permite que diversos workloads baseados em GPU (como IA, gráficos ou outros workloads de high performance computing) compartilhem as mesmas GPUs físicas, onde cada workload pode ser implantado em um sistema operacional guest diferente e pertencer a diferentes tenants em um ambiente de multi-tenancy.
Executamos workloads do MLPerf Inference 5.1 em um Dell PowerEdge XE9680 com oito NVIDIA SXM H200 141 GB HBM3e GPUs utilizando o VCF 9.0.0. As VMs utilizadas em nossos testes receberam apenas uma fração dos recursos bare metal. A Tabela 2 apresenta as configurações de hardware usadas para executar os workloads do MLPerf Inference 5.1 nos sistemas bare metal e virtualizados.
Tabela 2. Hardware e software para Dell PowerEdge XE9680
| Bare Metal | Virtual System | |
|---|---|---|
| Dell PowerEdge XE9680 | ||
| Processors | Intel(R) Xeon(R) Platinum 8568Y+ 96 cores | Intel(R) Xeon(R) Platinum 8568Y+ 96 cores |
| Logical processors | 192 | 192 total, 48 (25%) alocados para a VM para inferência, 144 disponíveis para outras VMs/workloads com isolamento total devido à virtualização. |
| GPU | 8x NVIDIA H200 141GB HBM3e | 8x virtualized NVIDIA H200-SXM-141GB (vGPU) |
| Accelerator Interconnect | 18x 4th Gen NVLink, 900GB/s | 18x 4th Gen NVLink, 900GB/s |
| Memory | 3 TB Host Memory | 3 TB |
| Alocação de Memória para VM | N/A | 2 TB (67%) alocados para a VM de inferência |
| Storage | 2 TB SSD, 5 TB CIFS | 2x 3.5TB SSD, 1x 7TB SSD |
| OS | Ubuntu 24.04 | Ubuntu 24.04 VM on VCF/ESXi 9.0.0.0.24755229 |
| CUDA | 12.8 and Driver 570.133 | 12.8 CUDA and Linux Driver 570.158.01 |
| TensorRT | TensorRT 10.1 | TensorRT 10.1 |
Os resultados do MLPerf Inference 5.1 apresentados na Tabela 3 mostram um excelente desempenho para large language models (Llama 3.1 405B e Llama 2 70B) e geração de imagens (SDXL – Stable Diffusion).
Tabela 3. Resultados do MLPerf Inference 5.1 usando 8x vGPUs no VCF 9.0 com Hardware Dell PowerEdge XE9680 com 8x H200 GPUs
| Benchmarks | Throughputs |
|---|---|
| Llama 3.1 405B Server (tokens / sec) | 277 |
| Llama 3.1 405B Offline (tokens / sec) | 547 |
| Llama 2 70B Server (tokens / sec) | 33385 |
| Llama 2 70B Offline (tokens / sec) | 34301 |
| Llama 2 70B – High Accuracy – Server (tokens per sec) | 33371 |
| Llama 2 70B – High Accuracy – Offline (tokens per sec) | 34486 |
| SDXL Server (samples / sec) | 17.95 |
| SDXL Offline (samples / sec) | 18.64 |
Na Figura 2, comparamos nossos resultados do MLPerf Inference 5.1 no VCF com os resultados da Dell em bare metal no mesmo Dell PowerEdge XE9680 com H200 GPUs. Ambos os resultados da Broadcom e da Dell estão publicamente disponíveis no website do MLCommons. Como a Dell submeteu apenas resultados do Llama 2 70B, a Figura 2 inclui o desempenho do MLPerf Inference 5.1 no VCF 9.0 versus bare metal para esses workloads e mostra que o VCF e o bare metal diferem em apenas 1% ou 2% no desempenho.
Desempenho do MLPerf Inference 5.1 no VCF com Processador Intel Xeon 6
A Intel e a Broadcom colaboraram para demonstrar as capacidades do VCF, capacitando clientes que utilizam apenas o processador Intel Xeon com aceleração AMX integrada para workloads de IA. Executamos workloads do MLPerf Inference 5.1, incluindo Llama 3.1 8B, DLRM-V2, R-GAT, Whisper e RetinaNet, no sistema apresentado na Tabela 4.
Tabela 4. Hardware e software para sistemas Intel
| Bare Metal | Virtual System | |
|---|---|---|
| Nome do Sistema | 1-node-2S-GNR_86C_BareMetal | 1-node-2S-GNR_86C_ESXi_172VCPU-VM |
| Processors | INTEL(R) XEON(R) 6787P 86 cores | INTEL(R) XEON(R) 6787P 86 cores |
| Logical processors | 172 | 172 vCPUs (43 vCPUs por nó NUMA) |
| Memory | 1 TB (16x 64 GB DDR5 1286400 MT/s[8000 MT/s]) | 921 GB |
| Storage | 1x 1.7 TB SSD | 1x 1.7 TB SSD |
| OS | CentOS Stream 9 | CentOS Stream 9 |
| Other software stack | 6.6.0-gnr.bkc.6.6.31.1.45.x86_64 | 6.6.0-gnr.bkc.6.6.31.1.45.x86_64, VMware ESXi 9.0.0.0.24755229 |
Workloads de IA, particularmente modelos menores, podem ser executados de forma eficiente em Intel Xeon CPUs com aceleração AMX usando o VCF, alcançando desempenho próximo ao bare metal enquanto se beneficiam da capacidade de gerenciamento e flexibilidade do VCF. Isso torna os processadores Intel Xeon CPUs um ótimo ponto de partida para organizações que embarcam em sua jornada de IA, pois podem aproveitar a infraestrutura existente.
Os resultados do MLPerf Inference 5.1 usando Processadores Intel Xeon no VCF mostram desempenho equivalente ao bare metal. Em casos onde os data centers não possuem aceleradores como GPUs disponíveis, ou os workloads de IA são menos exigentes em termos de computação, dependendo dos casos de uso do cliente, os workloads de AI/ML podem ser implantados em Processadores Intel Xeon no VCF para se beneficiarem da virtualização, aproveitando o desempenho equivalente ao bare metal, conforme mostrado na Figura 3.
Benchmarks do MLPerf Inference
Cada benchmark é definido por um Dataset e um Quality Target. A tabela a seguir resume os benchmarks nesta versão da suíte:
Tabela 5. Os benchmarks do MLPerf Inference 5.1
| Área | Tarefa | Modelo | Dataset | QSL Size |
|---|---|---|---|---|
| Language | LLM – Q&A | Llama 2 70B | OpenOrca | 24576 |
| Language | Summarization | Llama 3.1 8B | CNN Dailymail (v3.00, max_seq_len=2048) | 13368 |
| Language | Text Generation | Llama 3.1 405B | Subset of LongBench, LongDataCollections, Ruler, GovReport | 8313 |
| Vision | Object detection | RetinaNet | OpenImages (800×800) | 64 |
| Speech | Speech to text | Whisper | LibriSpeech | 1633 |
| Image | Image Generation | SDXL 1.0 | COCO-2014 | 5000 |
| R-GAT | Node Classification | R-GAT | IGBH | 788379 |
| Commerce | Recommendation | DLRM-DCNv2 | Criteo 4TB Multi-hot | 204800 |
| Commerce | Recommendation | DLRM | 1TB Click Logs | 204800 |
Em um cenário Offline, o gerador de workload (LoadGen) envia todas as consultas para o sistema sob teste (SUT) no início da execução. Em um cenário Server, o LoadGen envia novas consultas para o sistema sob teste de acordo com uma distribuição Poisson. Isso é mostrado na Tabela 6.
Tabela 6. Os cenários de teste do MLPerf Inference
| Cenário | Geração de Query | Duração | Samples por query | Latency constraint | Tail latency | Performance metric |
|---|---|---|---|---|---|---|
| Server | LoadGen sends new queries to the SUT according to a Poisson distribution | 270,336 queries and 60 seconds | 1 | Benchmark-specific | 99% | Maximum Poisson throughput parameter supported |
| Offline | LoadGen sends all queries to the SUT at start | 1 query and 60 seconds | At least 24,576 | None | N/A | Measured throughput |
Conclusão
O VCF oferece aos clientes múltiplas opções flexíveis para implantação de infraestrutura de IA, suporta múltiplos fornecedores de hardware e permite uma variedade de maneiras de habilitar workloads de IA que usam GPUs ou CPUs para computação.
Ao usar GPUs, as configurações virtualizadas das VMs utilizam apenas uma fração dos recursos de CPU e memória em nosso benchmarking e entregam desempenho de MLPerf Inference 5.1 equivalente ao bare metal, mesmo em pico de utilização da GPU — este é um benefício chave da virtualização. Isso permite que você utilize os recursos restantes de CPU e memória nesses sistemas para executar outros workloads com isolamento total, reduzir o custo da infraestrutura AI/ML e aproveitar os benefícios de virtualização do VCF para gerenciar data centers.
Os resultados de nossos testes de benchmark indicam que o VCF 9.0 se enquadra na "Zona Goldilocks" para workloads de AI/ML com desempenho comparável a ambientes bare metal.
O VCF também facilita o gerenciamento e o processamento rápido de workloads usando vGPUs, NVLinks flexíveis para conectar dispositivos e tecnologias de virtualização para usar a infraestrutura AI/ML para gráficos, training e inferência. A virtualização reduz o Total Cost of Ownership (TCO) de uma infraestrutura AI/ML, permitindo o compartilhamento de recursos de hardware caros entre múltiplos tenants.
Pronto para iniciar sua jornada de IA e ML?
Confira estes recursos úteis:
- Preencha este formulário para entrar em contato conosco!
- Leia o solution brief do VMware Private AI Foundation with NVIDIA.
- Saiba mais sobre o VMware Private AI Foundation with NVIDIA.
- Conecte-se conosco no Twitter em @VMwareVCF e no LinkedIn em VMware VCF.
Agradecimentos:
Gostaríamos de agradecer especialmente a Jia Dai (NVIDIA); Patrick Geary, Eddie Chao, Dexter Bermudez e Steven Phan (SuperMicro); Frank Han, Thaddeus Rogers, Minesh Patel e Manpreet Sokhi (Dell); Sajjid Reza, Mihir Rajesh Dattani, Manasa Kankanala e Komala B Rangappa (Intel); e Juan Garcia-Rovetta (Broadcom) por sua ajuda e apoio na conclusão deste trabalho.
Descubra mais no Blog VMware Cloud Foundation (VCF). Assine para receber os posts mais recentes por e-mail.
Precisa de ajuda com suas soluções de TI?
A VirtuAllIT Solutions oferece consultoria especializada em virtualização, cloud computing e infraestrutura tecnológica.