
Vinte anos de Amazon S3 e construindo o futuro
Vinte anos de Amazon S3 e a construção do futuro
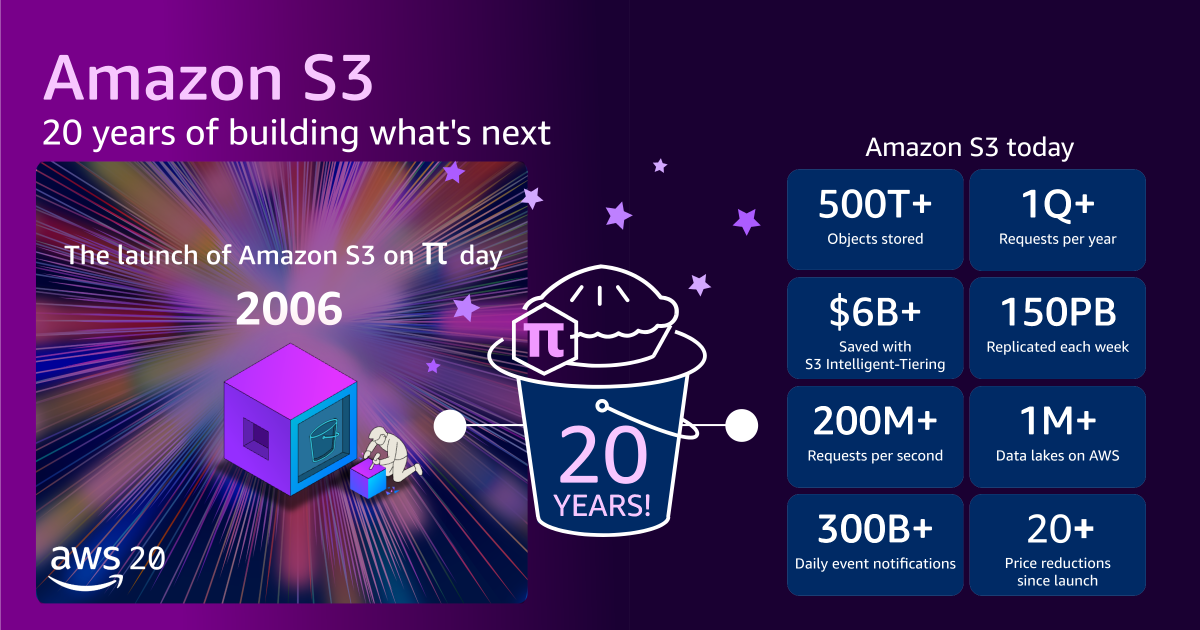
Há vinte anos, em 14 de março de 2006, o Amazon Simple Storage Service (Amazon S3) foi lançado discretamente com um modesto anúncio de um parágrafo na página "What’s New":
"Amazon S3 é um storage para a Internet. Ele foi projetado para tornar a computação em escala web mais fácil para desenvolvedores. O Amazon S3 fornece uma interface simples de web services que pode ser usada para armazenar e recuperar qualquer quantidade de dados, a qualquer momento, de qualquer lugar na web. Ele oferece a qualquer desenvolvedor acesso à mesma infraestrutura de armazenamento de dados altamente escalável, confiável, rápida e barata que a Amazon usa para operar sua própria rede global de sites."
Até a postagem do blog de Jeff Barr tinha apenas alguns parágrafos, escrita antes de ele pegar um avião para um evento de desenvolvedores na Califórnia. Sem exemplos de código. Sem demonstração. Muito pouca fanfarra. Ninguém sabia na época que esse lançamento moldaria toda a nossa indústria.
Os primeiros dias: Blocos de construção que simplesmente funcionam
Em sua essência, o S3 introduziu duas primitivas diretas: PUT para armazenar um objeto e GET para recuperá-lo posteriormente. Mas a verdadeira inovação foi a filosofia por trás disso: criar blocos de construção que lidassem com o trabalho pesado e indiferenciado, o que liberou os desenvolvedores para se concentrarem em trabalhos de nível superior.
Desde o primeiro dia, o S3 foi guiado por cinco fundamentos que permanecem inalterados hoje:
- Security significa que seus dados são protegidos por padrão.
- Durability é projetada para 11 noves (99.999999999%), e operamos o S3 para ser sem perdas.
- Availability é projetada em cada camada, com a suposição de que a falha está sempre presente e deve ser tratada.
- Performance é otimizada para armazenar virtualmente qualquer quantidade de dados sem degradação.
- Elasticity significa que o sistema cresce e diminui automaticamente à medida que você adiciona e remove dados, sem necessidade de intervenção manual.
Quando acertamos essas coisas, o serviço se torna tão direto que a maioria de vocês nunca precisa pensar em quão complexos esses conceitos são.
S3 hoje: Escala além da imaginação
Ao longo de 20 anos, o S3 permaneceu comprometido com seus fundamentos principais, mesmo enquanto crescia para uma escala difícil de compreender. Quando o S3 foi lançado pela primeira vez, ele oferecia aproximadamente um petabyte de capacidade total de storage em cerca de 400 storage nodes em 15 racks, abrangendo três data centers, com 15 Gbps de largura de banda total. Projetamos o sistema para armazenar dezenas de bilhões de objetos, com um tamanho máximo de objeto de 5 GB. O preço inicial era de 15 centavos por gigabyte.
Hoje, o S3 armazena mais de 500 trilhões de objetos e atende mais de 200 milhões de requisições por segundo globalmente em centenas de exabytes de dados em 123 Availability Zones em 39 AWS Regions, para milhões de clientes. O tamanho máximo do objeto cresceu de 5 GB para 50 TB, um aumento de 10.000 vezes. Se você empilhasse todos os milhões de hard drives do S3, eles alcançariam a Estação Espacial Internacional e quase voltariam.
Mesmo com o S3 crescendo para suportar essa escala incrível, o preço que você paga diminuiu. Hoje, a AWS cobra pouco mais de 2 centavos por gigabyte. Essa é uma redução de preço de aproximadamente 85% desde o lançamento em 2006. Em paralelo, continuamos a introduzir maneiras de otimizar ainda mais os gastos com storage por meio de storage tiers. Por exemplo, nossos clientes economizaram coletivamente mais de US$ 6 bilhões em custos de storage usando o Amazon S3 Intelligent-Tiering em comparação com o Amazon S3 Standard.
Nas últimas duas décadas, a API do S3 foi adotada e usada como um ponto de referência em toda a indústria de storage. Vários fornecedores agora oferecem ferramentas e sistemas de storage compatíveis com S3, implementando os mesmos padrões e convenções de API. Isso significa que as habilidades e ferramentas desenvolvidas para o S3 geralmente são transferíveis para outros sistemas de storage, tornando o cenário de storage mais acessível.
Apesar de todo esse crescimento e adoção pela indústria, talvez a conquista mais notável seja esta: o código que você escreveu para o S3 em 2006 ainda funciona hoje, inalterado. Seus dados passaram por 20 anos de inovação e avanços técnicos. Migramos a infraestrutura através de múltiplas gerações de discos e sistemas de storage. Todo o código para lidar com uma requisição foi reescrito. Mas os dados que você armazenou há 20 anos ainda estão disponíveis hoje, e mantivemos compatibilidade retroativa completa da API. Esse é o nosso compromisso em entregar um serviço que continuamente "simplesmente funciona".
A engenharia por trás da escala
O que torna o S3 possível nessa escala? Inovação contínua em engenharia. Grande parte do que se segue é extraída de uma conversa entre Mai-Lan Tomsen Bukovec, VP de Data and Analytics da AWS, e Gergely Orosz do The Pragmatic Engineer. A entrevista aprofundada explora mais detalhes técnicos para aqueles que desejam se aprofundar. Nos parágrafos seguintes, compartilho alguns exemplos:
- No coração da durability do S3 está um sistema de microservices que inspeciona continuamente cada byte em toda a frota. Esses serviços de auditoria examinam os dados e acionam automaticamente os sistemas de reparo no momento em que detectam sinais de degradação. O S3 é projetado para ser sem perdas: a meta de design de 11 noves reflete como o fator de replicação e a frota de re-replicação são dimensionados, mas o sistema é construído para que os objetos não sejam perdidos.
- Engenheiros do S3 usam métodos formais e raciocínio automatizado em produção para provar matematicamente a correção. Quando os engenheiros fazem check-in de código no subsistema de índice, provas automatizadas verificam se a consistência não regrediu. Essa mesma abordagem prova a correção na replicação entre Regions ou para políticas de acesso.
- Nos últimos 8 anos, a AWS tem reescrito progressivamente o código crítico para performance no caminho da requisição do S3 em Rust. A movimentação de blobs e o armazenamento em disco foram reescritos, e o trabalho está ativamente em andamento em outros componentes. Além da performance bruta, o sistema de tipos e as garantias de segurança de memória do Rust eliminam classes inteiras de bugs em tempo de compilação. Esta é uma propriedade essencial ao operar na escala e nos requisitos de correção do S3.
- O S3 é construído sobre uma filosofia de design: "A escala é sua vantagem". Os engenheiros projetam sistemas para que o aumento da escala melhore os atributos para todos os usuários. Quanto maior o S3 se torna, mais descorrelacionadas as workloads ficam, o que melhora a confiabilidade para todos.
Olhando para o futuro
A visão para o S3 se estende além de ser um serviço de storage para se tornar a base universal para todas as workloads de dados e IA. Nossa visão é simples: você armazena qualquer tipo de dado uma única vez no S3 e trabalha com ele diretamente, sem mover dados entre sistemas especializados. Essa abordagem reduz custos, elimina a complexidade e remove a necessidade de múltiplas cópias dos mesmos dados.
Aqui estão alguns lançamentos de destaque dos últimos anos:
- S3 Tables – Tabelas Apache Iceberg totalmente gerenciadas com manutenção automatizada que otimizam a eficiência de consulta e reduzem o custo de storage ao longo do tempo.
- S3 Vectors – Storage nativo de vetores para busca semântica e RAG, suportando até 2 bilhões de vetores por índice com latência de consulta inferior a 100ms. Em apenas 5 meses (julho a dezembro de 2025), você criou mais de 250.000 índices, ingeriu mais de 40 bilhões de vetores e realizou mais de 1 bilhão de consultas.
- S3 Metadata – Metadata centralizada para descoberta instantânea de dados, eliminando a necessidade de listar recursivamente buckets grandes para catalogação e reduzindo significativamente o tempo de obtenção de insights para grandes data lakes.
Cada uma dessas capacidades opera com a estrutura de custos do S3. Você pode lidar com múltiplos tipos de dados que tradicionalmente exigiam bancos de dados caros ou sistemas especializados, mas que agora são economicamente viáveis em escala.
De 1 petabyte a centenas de exabytes. De 15 centavos a 2 centavos por gigabyte. De um simples object storage à base para IA e analytics. Em tudo isso, nossos cinco fundamentos – security, durability, availability, performance e elasticity – permanecem inalterados, e seu código de 2006 ainda funciona hoje.
Brindemos aos próximos 20 anos de inovação no Amazon S3.
— seb
Precisa de ajuda com suas soluções de TI?
A VirtuAllIT Solutions oferece consultoria especializada em virtualização, cloud computing e infraestrutura tecnológica.